
最新修改 2025年 6月 26日 by amiao
随着科技的飞速发展,人工智能已深入到各个领域。为响应古籍活化利用号召,推动大语言模型与古籍处理深度融合,以古籍智能化的研究为目的,本项目推出了一系列古籍处理领域大语言模型:荀子古籍大语言模型。
这样就不用怕古籍文章看不懂啦,荀子系列大语言模型可以帮助你解读古籍文章主题、抽取关键信息,人物、地点,事件等,还能进行词语分析和生成诗词。
项目介绍
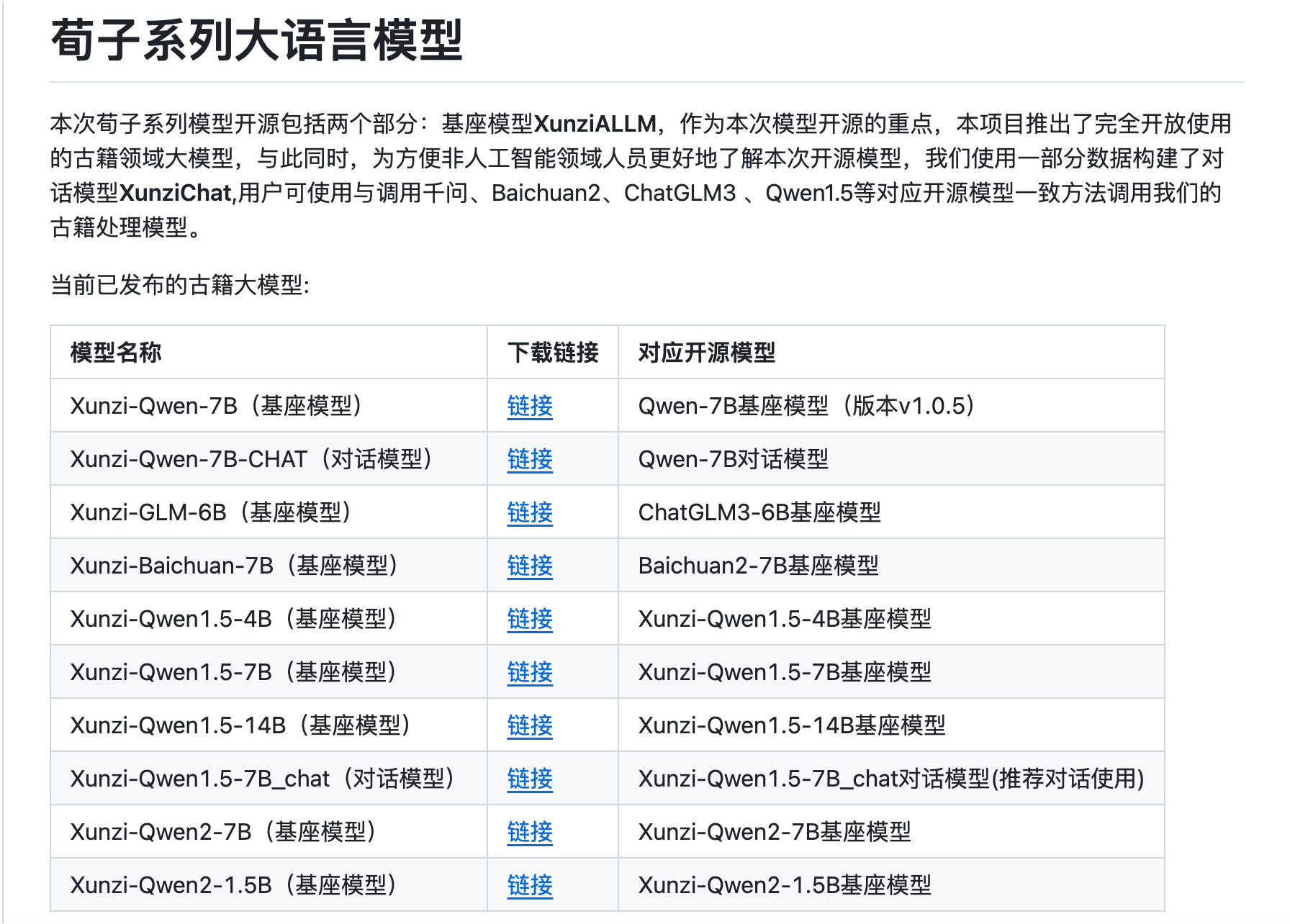
荀子系列模型开源包括两个部分:基座模型XunziALLM,推出了完全开放使用的古籍领域大模型,与此同时,为方便非人工智能领域人员更好地了解本次开源模型,我们使用一部分数据构建了对话模型XunziChat,用户可使用与调用千问、Baichuan2、ChatGLM3 、Qwen1.5等对应开源模型一致方法调用我们的古籍处理模型。
由于同时发布了基座模型,用户也可以根据自己的需求,使用本地的训练语料微调荀子基座模型,使得其能够在古籍下游处理任务上取得更佳的处理性能。
项目截图
亮点
- 古籍智能标引,荀子模型具备强大的古籍文献标引能力,能够对古籍中的内容进行高质量主题标引,帮助研究人员快速了解文章主题。
- 古籍信息抽取,荀子模型能够自动从古籍中抽取关键信息,如人物、事件、地点等,大大节省了研究人员的信息整理时间。
- 诗歌生成:荀子模型还具备诗歌生成的能力,能够根据给定的主题或关键词,自动生成符合语法规则和韵律要求的古诗,为诗词爱好者提供创作灵感。
- 古籍高质量翻译:对于那些难以理解的古籍文献,荀子模型能够提供高质量的翻译服务,帮助研究人员更好地理解原文含义。
- 阅读理解:荀子模型能够对给出的古文文本进行分析解释,实现对古籍文本的自动阅读。
- 词法分析:荀子模型可以完成古籍文本的自动分词和词性标注,能够有效提升语言学工作者的研究效率。
- 自动标点:荀子大模型可以快速完成古籍文本的断句和标点,提升研究者以及业余爱好者对古籍文本的阅读体验。