


阿喵前言
现在本地跑大模型(LLM)越来越火,但最让玩家头疼的就是:我这破电脑到底能不能跑动这个模型?兴冲冲下了一个几十 GB 的模型,结果一运行直接 OOM(内存溢出),或者每秒只蹦一个词,简直折磨。
今天阿喵分享的这个 llmfit,就是专门解决这种“硬件焦虑”的。它不需要你懂复杂的参数计算,只要一条命令,它就能把你的电脑硬件翻个底朝天,然后告诉你:这个模型能跑,那个模型太卡,这个量化版本最适合你。
项目介绍
llmfit 是一款开源的终端工具,旨在为用户提供硬件感知的模型推荐。它通过自动检测系统的 RAM、CPU 和 GPU 规格,从质量、速度、适配度和上下文四个维度进行综合评分。无论你是想跑 Llama 3、DeepSeek 还是 Qwen,它都能给出最专业的“适配方案”。
截图
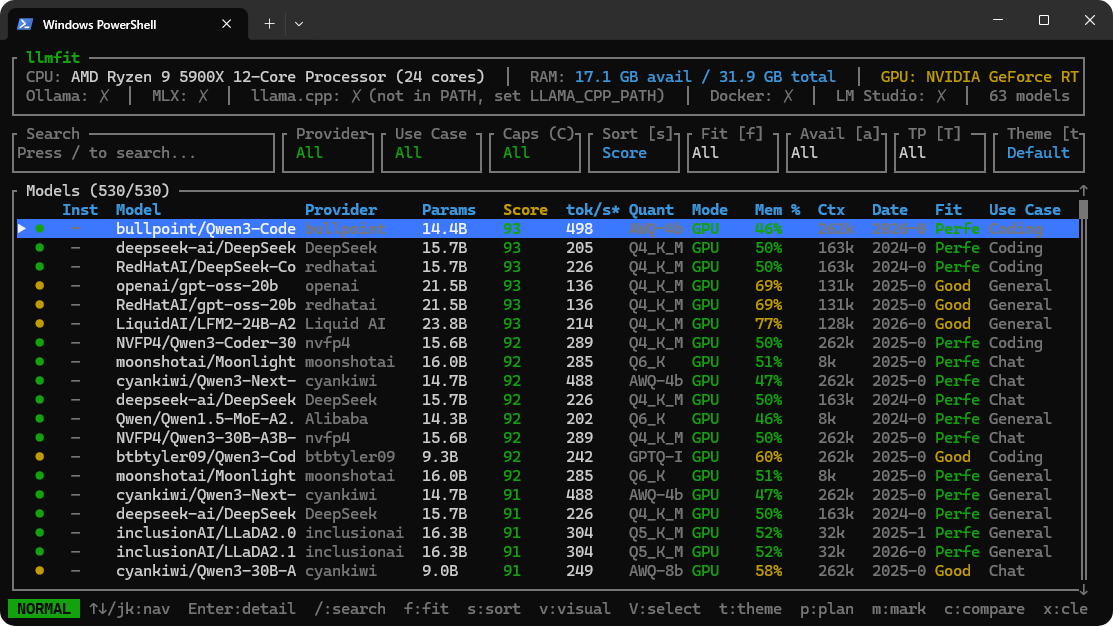
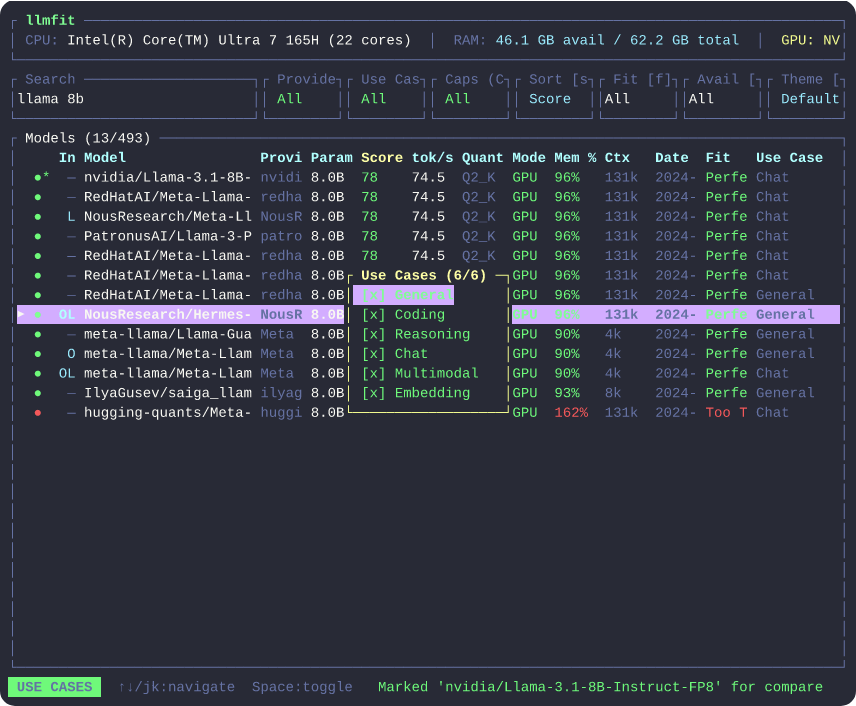
核心特色
- 多维度精准评分:不仅仅看内存够不够,还会评估:
- 质量 (Quality):参数量、量化惩罚和模型声誉。
- 速度 (Speed):基于带宽的预估生成速度(tokens/sec)。
- 适配度 (Fit):内存利用率是否处于 50-80% 的“甜点区”。
- 上下文 (Context):评估在不同上下文长度下的内存占用。
- 智能量化策略:它不会盲目推荐,而是会尝试从 Q8_0 到 Q2_K 逐级匹配,帮你找出能装进显存且质量最高的那个版本。
- 硬核架构支持:原生支持 MoE(混合专家模型),能自动计算 Mixtral 或 DeepSeek 的实际激活参数内存,避免因为模型总参数量大而被误判。
- 强大的 TUI 与 Web 仪表盘:默认提供类 Vim 操作的交互式终端界面,甚至还会自动在后台开启一个 Web 页面,让你在浏览器里直观查看硬件报告。
- 主流运行时集成:完美联动 Ollama、llama.cpp、MLX、LM Studio 等。如果检测到你已经安装了这些工具,它能直接通过 TUI 一键下载并安装模型。
- 硬件规划模式 (Plan):不仅能测现在的硬件,还能帮你“做梦”——输入一个目标模型,它会告诉你还需要升级多少显存或内存。
使用说明
工具支持全平台安装,操作逻辑非常现代化:
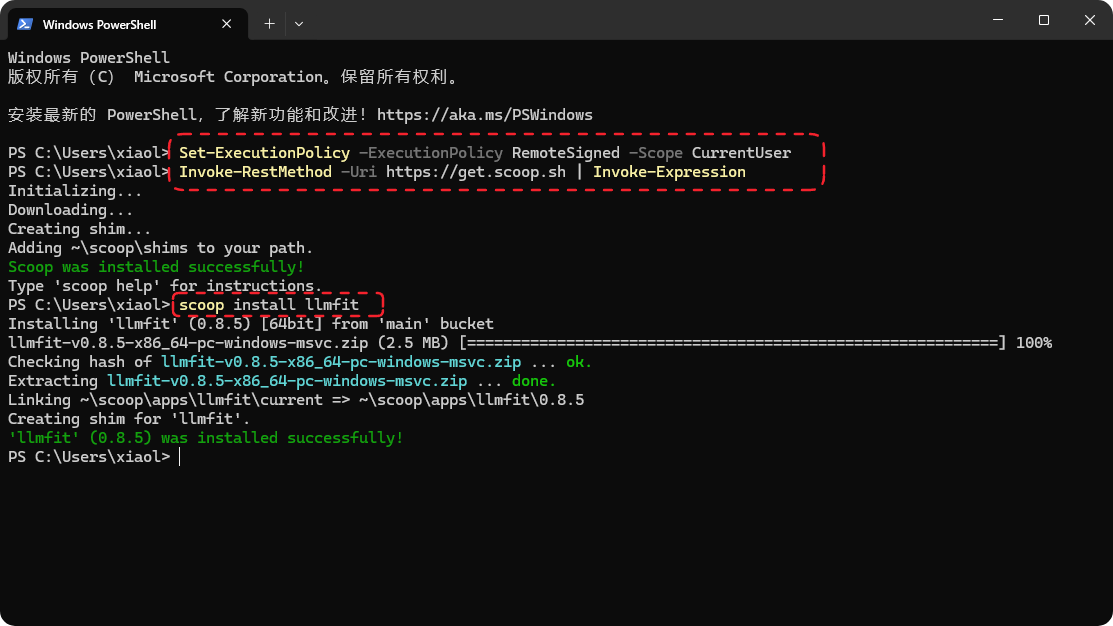
- 快速安装(如下图):
- macOS / Linux:
brew install llmfit或使用一键脚本。 - Windows powershell中执行:
scoop install llmfit
如果你的电脑没装scoop,则打开powershell,输入下面指令装scoop - Set-ExecutionPolicy -ExecutionPolicy RemoteSigned -Scope CurrentUser
- Invoke-RestMethod -Uri https://get.scoop.sh | Invoke-Expression
- macOS / Linux:
- 启动 TUI:安装完后直接在powershell中输入
llmfit。在界面中你可以看到顶部显示的硬件信息,下方的表格则列出了适配的模型。 - 交互操作:使用
j/k浏览,按d下载模型,按p进入硬件规划模式。 - CLI 模式:如果你只想在脚本里调用,可以使用
llmfit --cli或llmfit recommend --json获取机器可读的数据。
项目获取
- GitHub 源码:https://github.com/AlexsJones/llmfit/
- 项目官网:https://llmfit.axjns.dev/
这种把复杂的硬件参数转化为直观“适配等级”的工具,极大降低了普通用户折腾本地 AI 的门槛。如果你正打算在自己的电脑上跑一个私人助理,先让 llmfit 给你的电脑做个全身检查吧!
